
How to access, cite, and defend web datasets in academic research

We’re used to getting questions about accessing structured web data. But recently, we’ve been fielding a different kind of use case. Researchers and scientists have been asking about data citation conventions and how to defend research citing web datasets for peer review. As you might expect, we published our answers in the new Guide to Citing Web Datasets for Academic Researhers.
The New Data Commodity
Web data is so ubiquitous it has become commoditized. Still, acquiring data and processing it into a machine readable format presents a growing technological challenge. It means investing heavily in computing resources and software development to deliver a crawling and structuring solution at scale – representing a significant barrier for most research projects.
Fortunately, economies of scale enable anyone with even a modest budget to extract structured datasets. In fact, you can use the very same enterprise class technology trusted by a growing number of industry leaders. Since you pay per use, the solution addresses the needs and budget constraints of any consumer of data – ranging from students to large scale commercial data operations. Still, the challenge of peer review gets complicated when you need to cite and defend datasets generated by a third party.
The Challenge of Coverage Measurement
When it comes to data measurement, the first question is often “How big is your sample?”. Unfortunately, any figure or even percentage estimate would be misleading at best. The web is a constantly evolving and fragmented collection of unstructured data. Extracting that data and then structuring it as a prerequisite for analysis means making intelligent compromises. From a business and technology perspective, the meaningful question is “what is the best possible coverage we can provide given finite resources?” Answering that question is an ongoing technological challenge that is driving phenomenal growth of the emerging Data-as-a-Service solutions category.
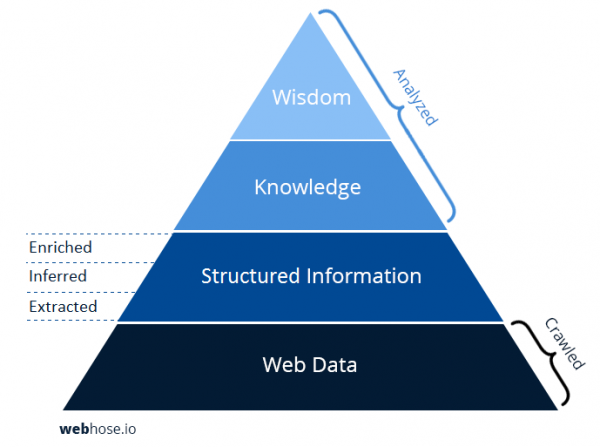
Dataset breakdown – extracted, inferred, and enriched fields
Webz.io structures web data into extracted fields, inferred fields, and enriched fields. Every source we crawl is identified as a “post”, an indexed record matching a specific news article, blog post, or online discussion post. We then extract standard fields common to these source types, including URL, title, body text, and associated online discussion posts such as comments. Data coverage supports 240 languages in virtually every country and territory connected to the Internet.
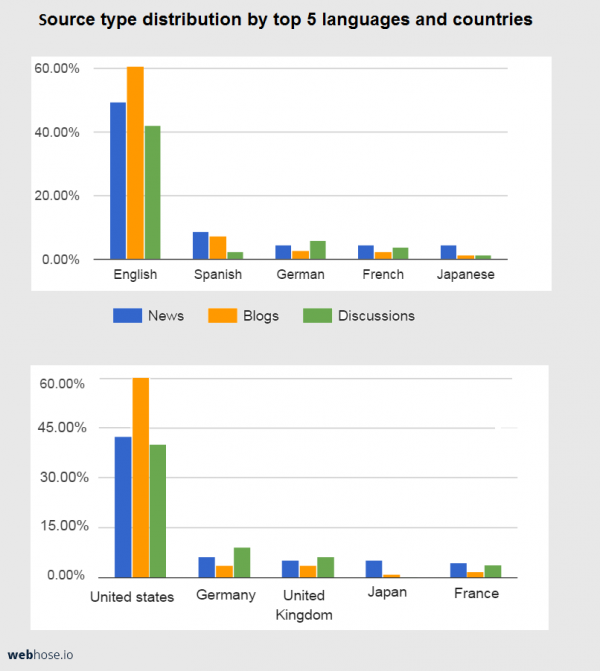
We focus on three types of web data sources:
- News media – news agencies, article publications, and magazines
- Blogs – individual bloggers, large blogging services such as blogger, brands
- Online discussions – message boards, commenting widgets, and review sites
Anyone can start out with a free 10-day trial account that supports up to 1000 requests. That means you can tap into millions of pages to analyze social media, news, and actual natural language expressions. Research fields range from finance and media to cybersecurity and machine learning.
Discover how to tap into web datasets>




